The 6th week was the most challenging and hardest week.
I started by the parallelization of the Image Comparison program.
The first challenge was to code this program so that I was able to implement a parallelization.
During the first week I realized that the only way to used kernels,blocks, and threads I needed a for loop.
This for loop needed to be where the program was processing a big number of data. This is necessary so that the CUDA programming is effective and makes a difference in the speed of thee program.
In order to create this for loop we needed to get rid of a while loop that was making the processing of the data.
In order to make this possible I needed to work with my co-worker Rida(programmer of the program), she was the only one able to create this for loop without affecting the way data was being read.
Once the program was finished I worked on the parallelization.
Challenges:
The program was not compiling with a simple CUDA parallelization, after working with it for several hours and fixing multiple errors in the program, I found out that the problem was not in the parallelization.
The major problem was that Stampede's OpenCV module did not have CUDA support built in. This is what completely stopped me from continuing the parallelization of this program.
The next step was to create a ticket about the problem and wait for the people in charge of Stampede to install it for me.
While this problem was fixed I was assigned another project dealing with Tesseract-OCR tool, the purpose of this was to find a tool and parallelize it, so that it would work along my co-worker's Image Comparison Program.
My first challenge was to know what this program was and the use of it.
Apparently this program reads embedded text in pictures and saves it or displays it for you.
I had found this tool as a normal program, the only problem with it was that it was not really successful at reading the text from images.
Challenges:
Make this tool work properly.
Make this program parallel to work with CUDA.
In order to make this program work with CUDA I needed to have the actual code of the program.
The next challenge was to code or find this tool already programmed and parallelize it.
After finding the code of Tesseract tool I was able to make changes to it so I could make it work with directories by extracting many pictures of that directory.
After making this program work correctly, I started making several tests in different cases.
For example:
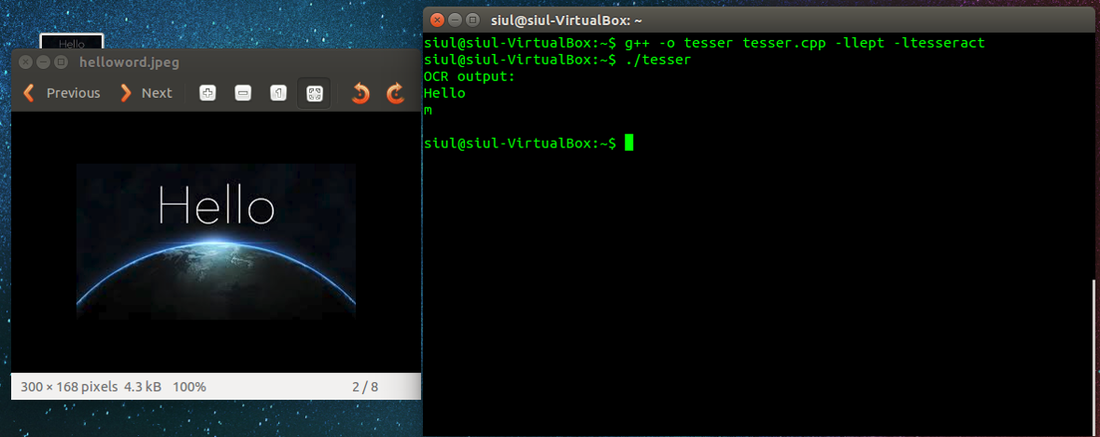
Cases in where the images contained well written letters.
I started by the parallelization of the Image Comparison program.
The first challenge was to code this program so that I was able to implement a parallelization.
During the first week I realized that the only way to used kernels,blocks, and threads I needed a for loop.
This for loop needed to be where the program was processing a big number of data. This is necessary so that the CUDA programming is effective and makes a difference in the speed of thee program.
In order to create this for loop we needed to get rid of a while loop that was making the processing of the data.
In order to make this possible I needed to work with my co-worker Rida(programmer of the program), she was the only one able to create this for loop without affecting the way data was being read.
Once the program was finished I worked on the parallelization.
Challenges:
- There are no arrays to store memory or copy memory from
- Know what to parallelize
- Kernel set up
- Device functions set up
- Number of possible threads set up
The program was not compiling with a simple CUDA parallelization, after working with it for several hours and fixing multiple errors in the program, I found out that the problem was not in the parallelization.
The major problem was that Stampede's OpenCV module did not have CUDA support built in. This is what completely stopped me from continuing the parallelization of this program.
The next step was to create a ticket about the problem and wait for the people in charge of Stampede to install it for me.
While this problem was fixed I was assigned another project dealing with Tesseract-OCR tool, the purpose of this was to find a tool and parallelize it, so that it would work along my co-worker's Image Comparison Program.
My first challenge was to know what this program was and the use of it.
Apparently this program reads embedded text in pictures and saves it or displays it for you.
I had found this tool as a normal program, the only problem with it was that it was not really successful at reading the text from images.
Challenges:
Make this tool work properly.
Make this program parallel to work with CUDA.
In order to make this program work with CUDA I needed to have the actual code of the program.
The next challenge was to code or find this tool already programmed and parallelize it.
After finding the code of Tesseract tool I was able to make changes to it so I could make it work with directories by extracting many pictures of that directory.
After making this program work correctly, I started making several tests in different cases.
For example:
Cases in where the images contained well written letters.
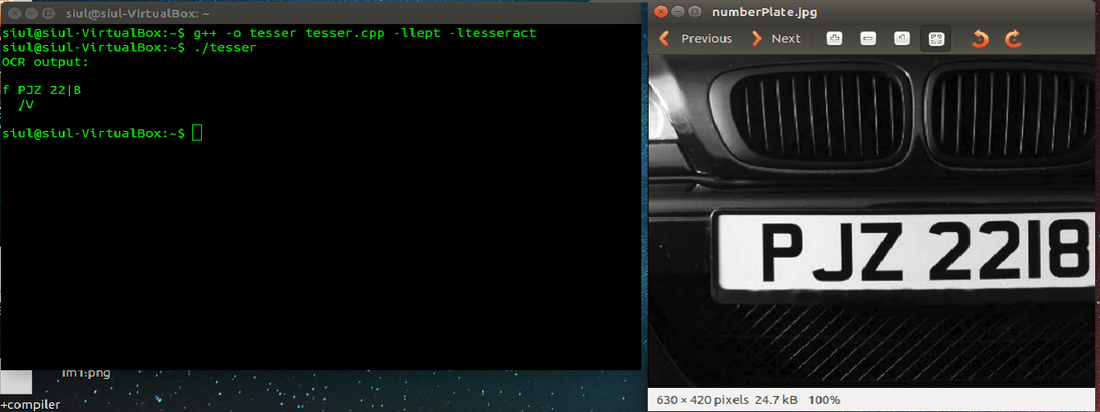
Cases with more realistic situations like reading from a car's plates.
Images with hand written font, which was a complete complication for the program to read.

